|
Мы приносим глубочайшие извинения за длинную задержку при подготовке этого поста. Сегодня мы публикуем анализ самообучающихся решений, присланных на конкурс по программированию, и вручаем два специальных приза.
Английская версия этой записи — на GitHub.
Итак, 9 из присланных решений оказались самообучающимися. Идея самообучения такова: поскольку все слова выбираются из конечного словаря, а не-слова генерируются случайно, то всякая строка, которая была представлена тестируемой программе повторно, с большей вероятностью окажется словом, чем не-словом. При достаточно продолжительном тестировании большинство слов из словаря успеют повториться, тогда как для не-слов случайные повторения встречаются гораздо реже.
Чтобы пронаблюдать поведение самообучающихся решений, мы протестировали их на 1 000 000 блоков. Тестировать на таком количестве блоков все решения было бы нереально, но эти девять оказались достаточно быстрыми.
На графике ниже показана зависимость процента правильных ответов от числа обработанных блоков. Обратите внимание, что горизонтальная шкала — логарифмическая. |
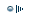 Главная
Главная 



