

ETERNUS DX – дисковые массивы, что там внутри
Рассмотрим более подробно, что у зайчика внутри какой функционал и механизмы присутствуют в дисковых массивах ETERNUS DX. Как уже писал ранее,
первые дисковые массивы были разработаны более 40 лет назад для
мейнфреймов FUJITSU. Собственно, это во многом определило направленность
всего семейства на использование дополнительных и расширенных
аппаратных механизмов, направленных на увеличение надежности хранения
данных. При этом развитие продуктовой линейки двигалось «сверху вниз» —
изначально были только High-End модели, а около 20 лет назад на базе
этих моделей и существующих технологий появились модели среднего и
младшего уровня.
Во всех массивах поддерживаются основные уровни RAID: 0, 1, 10, 5. 50, 6. В High-End есть определенные жесткие требования по количеству дисков в RAID-группе и уровнях RAID, которые могут быть использованы. При этом есть еще и ряд требований относительно того, как должны располагаться диски одной RAID-группы между дисковыми полками. Для систем среднего и начального уровня таких жестких ограничений нет. Понятно, что намного лучше с точки зрения и производительности, и надежности хранения разместить диски одной группы в разных дисковых полках – тогда выход из строя, например, контроллера дисковой полки или дисковой полки целиком позволит продолжить работать с данными группы. С другой стороны, подобные жесткие правила для систем начального и среднего уровня существенно снизят гибкость работы всей системы. Поэтому нет никаких проблем создать, например, дисковую группу из всех дисков на одной полке для систем начального или среднего уровня, но, при этом High-End массив не позволит создать такую группу. Хотя, повторюсь, для систем начального и среднего уровня тоже рекомендуется разносить диски одной группы по разным полкам – хуже от этого точно не будет.
Во всех системах поддерживаются диски SAS, NL-SAS и SSD. Кроме того, поддерживаются полки 2.5” и 3.5” дисков. В полку можно в произвольной последовательности устанавливать диски различных типов. Понятно, что в одну группу диски разных типов объединять, мягко скажем, не рекомендуется. Не существует каких-либо ограничений по количеству SSD-дисков в системе. Кроме ограничений бюджета, целесообразности и здравого смысла.
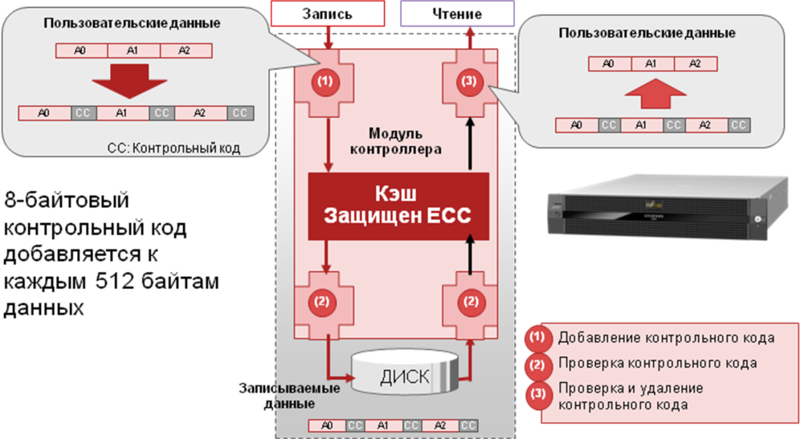
Все диски низкоуровнево форматируются особым образом блоками по 520 байт. Из них 512 – под данные, 8 – под контроль целостности. При записи система рассчитывает контрольный код для каждого блока из 512 байт и записывает его следом за блоком. На этапе чтения блока данные обязательно проверяются на целостность, контрольный блок отбрасывается и на выход системы к хостам передаются уже оригинальные блоки без контрольного кода. Также, если у системы есть свободные вычислительные ресурсы и ресурсы ввода-вывода загружены не на 100%, то в фоновом режиме также проверяется правильность контрольного кода. Этот механизм называется Data Block Guard.
Следующим механизмом увеличения надежности хранения является Redundant Copy. Прежде чем рассказать об этом механизме – несколько страшилок. Выход из строя жесткого диска – это, разумеется, плохо. Причем, поскольку количество блоков и секторов растет вместе с ростом емкости жесткого диска, то растет и вероятность выхода из строя всего устройства. Конечно, вероятность выхода из строя диска на 3ТБ не в 3 раза больше, чем диска в 1 ТБ, но, тем не менее, RAID6 в промышленном исполнении появился-таки относительно недавно. А теперь рассмотрим жизнь среднестатистической RAID-группы – с огромной долей вероятности это диски из одной заводской партии, которые проработали одинаковое количество часов в одинаковых условиях, тут один из них сломался, начался процесс перестроения группы, и, стало быть, возросла нагрузка на остальные диски. Ну, а дальше уже теория отказов, матстатистика плюс некая мистика совпадений начинают делать свое дело. Иногда еще заодно и проверяя наличие и целостность резервных копий :).
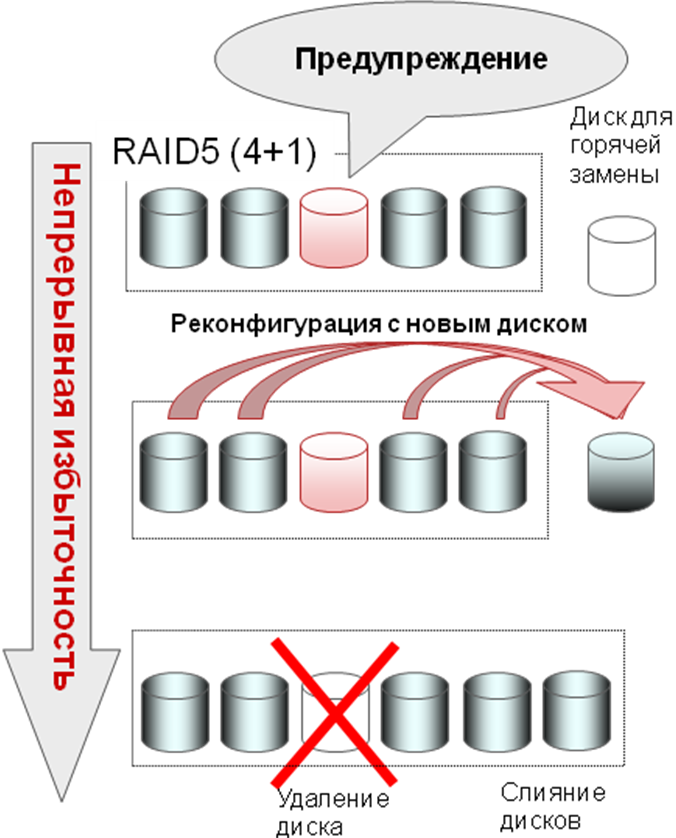
Посмотрим, что реализовано в ETERNUS DX, чтобы существенно уменьшить вероятность плохих сценариев. Дисковая система постоянно следит за состоянием жестких дисков. Сегодня по изрядному количеству признаков, таких, как увеличение среднего времени отклика с диска, роста количества повторных циклов чтения/записи, когда диск с первого раза не смог считать/записать тот или иной блок, росту количества срабатываний механизма Data Block Guard, сам дисковый массив по результатам постоянного сбора и анализа этой информации со всех жестких дисков может с очень высокой степенью вероятности предсказать, что тот или иной жесткий диск скоро выйдет из строя. И заблаговременно начать перенос данных с этого диска на диск горячей замены. Причем «подозрительный» диск на время этого процесса остается полностью доступен по чтению, блокируются и перенаправляются на новый диск только операции записи. Таким образом, существенно увеличивается надежность работы дисковой группы.
При этом подобное событие является полностью гарантийным случаем. А стандартная гарантия, к слову сказать, для всех ETERNUS DX составляет 3 года.
Во всех массивах поддерживаются основные уровни RAID: 0, 1, 10, 5. 50, 6. В High-End есть определенные жесткие требования по количеству дисков в RAID-группе и уровнях RAID, которые могут быть использованы. При этом есть еще и ряд требований относительно того, как должны располагаться диски одной RAID-группы между дисковыми полками. Для систем среднего и начального уровня таких жестких ограничений нет. Понятно, что намного лучше с точки зрения и производительности, и надежности хранения разместить диски одной группы в разных дисковых полках – тогда выход из строя, например, контроллера дисковой полки или дисковой полки целиком позволит продолжить работать с данными группы. С другой стороны, подобные жесткие правила для систем начального и среднего уровня существенно снизят гибкость работы всей системы. Поэтому нет никаких проблем создать, например, дисковую группу из всех дисков на одной полке для систем начального или среднего уровня, но, при этом High-End массив не позволит создать такую группу. Хотя, повторюсь, для систем начального и среднего уровня тоже рекомендуется разносить диски одной группы по разным полкам – хуже от этого точно не будет.
Во всех системах поддерживаются диски SAS, NL-SAS и SSD. Кроме того, поддерживаются полки 2.5” и 3.5” дисков. В полку можно в произвольной последовательности устанавливать диски различных типов. Понятно, что в одну группу диски разных типов объединять, мягко скажем, не рекомендуется. Не существует каких-либо ограничений по количеству SSD-дисков в системе. Кроме ограничений бюджета, целесообразности и здравого смысла.
Все диски низкоуровнево форматируются особым образом блоками по 520 байт. Из них 512 – под данные, 8 – под контроль целостности. При записи система рассчитывает контрольный код для каждого блока из 512 байт и записывает его следом за блоком. На этапе чтения блока данные обязательно проверяются на целостность, контрольный блок отбрасывается и на выход системы к хостам передаются уже оригинальные блоки без контрольного кода. Также, если у системы есть свободные вычислительные ресурсы и ресурсы ввода-вывода загружены не на 100%, то в фоновом режиме также проверяется правильность контрольного кода. Этот механизм называется Data Block Guard.
Следующим механизмом увеличения надежности хранения является Redundant Copy. Прежде чем рассказать об этом механизме – несколько страшилок. Выход из строя жесткого диска – это, разумеется, плохо. Причем, поскольку количество блоков и секторов растет вместе с ростом емкости жесткого диска, то растет и вероятность выхода из строя всего устройства. Конечно, вероятность выхода из строя диска на 3ТБ не в 3 раза больше, чем диска в 1 ТБ, но, тем не менее, RAID6 в промышленном исполнении появился-таки относительно недавно. А теперь рассмотрим жизнь среднестатистической RAID-группы – с огромной долей вероятности это диски из одной заводской партии, которые проработали одинаковое количество часов в одинаковых условиях, тут один из них сломался, начался процесс перестроения группы, и, стало быть, возросла нагрузка на остальные диски. Ну, а дальше уже теория отказов, матстатистика плюс некая мистика совпадений начинают делать свое дело. Иногда еще заодно и проверяя наличие и целостность резервных копий :).
Посмотрим, что реализовано в ETERNUS DX, чтобы существенно уменьшить вероятность плохих сценариев. Дисковая система постоянно следит за состоянием жестких дисков. Сегодня по изрядному количеству признаков, таких, как увеличение среднего времени отклика с диска, роста количества повторных циклов чтения/записи, когда диск с первого раза не смог считать/записать тот или иной блок, росту количества срабатываний механизма Data Block Guard, сам дисковый массив по результатам постоянного сбора и анализа этой информации со всех жестких дисков может с очень высокой степенью вероятности предсказать, что тот или иной жесткий диск скоро выйдет из строя. И заблаговременно начать перенос данных с этого диска на диск горячей замены. Причем «подозрительный» диск на время этого процесса остается полностью доступен по чтению, блокируются и перенаправляются на новый диск только операции записи. Таким образом, существенно увеличивается надежность работы дисковой группы.
При этом подобное событие является полностью гарантийным случаем. А стандартная гарантия, к слову сказать, для всех ETERNUS DX составляет 3 года.


